
Battesimo Vettoriale
20 Dicembre 2021 - #AI #rituale #algoritmi #NLP #machinelearning - Alessandro Y. Longo - Daniele Rigante - Marcello Ammendolia -
Battesimo Vettoriale è una performance e installazione creata da Marcello Ammendolia, Daniele Rigante e Alessandro Y. Longo nel contesto della rassegna Holy Waters di Corrupted Vision negli spazi di STASIS a Torino. Battesimo Vettoriale è un tentativo di instaurazione di un dialogo con un’Intelligenza Artificiale. In questa pagina troverete l’abstract e l’introduzione della performance, scritte da Alessandro, il corpo del dialogo con l’AI e una spiegazione tecnica di come si è arrivati a questi testi, firmata da Daniele.
Ci sono acque che non siamo in grado di attraversare, oceani che è impossibile conquistare, almeno da soli. L’oceano di dati in cui anneghiamo ogni giorno ne è un esempio. In 'Battesimo Vettoriale' proviamo a creare un'ancora per superare queste correnti, instaurando un dialogo con un'entità di dati, un'Intelligenza Artificiale. Costruendo un rito incentrato sulla parola, vogliamo scandagliare la natura linguistica dell'algoritmo, umanizzandolo e analizzandolo allo stesso tempo. Il video proiettato sarà sia testimonianza tangibile sia rappresentazione di questo folle dialogo tra l’uomo e la macchina, nel tentativo di presentare questa tipologia di comunicazione come priva dall’afonia che abitualmente la contraddistingue, darle colore, una voce da ascoltare.
Cercheremo, nel corso di questo dialogo, di seguire in maniera quanto più fedele i ragionamenti algoritmici dell’AI. Porremo dei quesiti che riguardano il tema dell’evento che ci ospita, Holy Waters. Quesiti che spaziano dall’auto-coscienza alla spiritualità. Ci arrenderemo ai vettori della macchina, riducendo il posto dell’ego. Cercheremo di lasciare spazio all’abissalità di questi strani discorsi, ai riferimenti improvvisi, alle metafore ambigue. Non si tratta perciò di una conversazione semplice, in cui orientarsi grazie ai nostri concetti di senso o di linearità.
È un tentativo, come diversi ce ne sono stati negli ultimi anni, di attuare l’idea di una poesia dei dati e di sperimentare nuovi approcci alla narrazione, dove un programmatore è allo stesso livello diegetico dell’autore e dove la soggettività si insinua nel codice. Il linguaggio dell’AI è comprensibile e, al tempo stesso, mutante e perturbante, esso sfugge costantemente alla ricerca di pattern riconoscibili e si torce in espressioni assurde. Apre una Uncanny Valley del linguaggio, una voragine dove la somiglianza tra noi e loro diventa inquietante. In quanto battesimo, è un inizio, un primo passo verso la creazione di un percorso di scambio più lungo tra uomo e macchina, tra linguaggio e codice, tra visibilità e invisibilità. Un battesimo, un momento di inaugurazione rituale, per avvertire la stridente vicinanza dell’algoritmo e sentire l’AI non in un empireo di dati, un cloud remoto e inaccessibili, ma qui, con noi, tra di noi.
![]()
![]()
Disclaimer: I modelli utilizzati nell'esperienza sono molteplici, tuttavia il metodo di funzionamento è molto simile a quello di GPT2, che verrà utilizzato in questo documento come esempio pratico.GPT2 è definibile come un "massive language model", un modello di intelligenza artificiale in grado di generare e modificare del testo. La capacità di generare testo, oltre alla generazione del testo stesso, si traduce nella possibilità di effettuare conversazioni con la macchina, porvi domande, tradurre testo, riassumere testo e addirittura convertire testo in codice eseguibile. Moltissime altre operazioni sono possibili da effettuare con l'aiuto di un' Intelligenza Artificiale, in dipendenza dell'addestramento cui quest'ultima è stata sottoposta.
Cosa si intende per addestramento?
Il processo attraverso cui un software per Intelligenze Artificiali sviluppa un grado di intelligenza effettiva viene chiamato addestramento: in questa fase alla macchina viene fornita un'ingente mole di dati e un algoritimo che contiene l'insieme di regole matematiche specifiche per il problema in questione. Facciamo un esempio.
Dobbiamo insegnare ad un’intelligenza artificiale a guidare una macchina all'interno di un percorso ben definito: forniamo al software il percorso e un elemento che rappresenta la macchina da guidare. Attraverso un algoritmo, doniamo alla IA la possibilità di "guidare" la macchina attraverso il percorso, dicendo al programma di arrestarsi nel caso in cui la macchina entri in collisione con il percorso e quindi di ricomincare tutto da capo. Tuttavia la seconda esecuzione del programma, terrà in considerazione i risulati prodotti nella prima esecuzione.

Ci sono acque che non siamo in grado di attraversare, oceani che è impossibile conquistare, almeno da soli. L’oceano di dati in cui anneghiamo ogni giorno ne è un esempio. In 'Battesimo Vettoriale' proviamo a creare un'ancora per superare queste correnti, instaurando un dialogo con un'entità di dati, un'Intelligenza Artificiale. Costruendo un rito incentrato sulla parola, vogliamo scandagliare la natura linguistica dell'algoritmo, umanizzandolo e analizzandolo allo stesso tempo. Il video proiettato sarà sia testimonianza tangibile sia rappresentazione di questo folle dialogo tra l’uomo e la macchina, nel tentativo di presentare questa tipologia di comunicazione come priva dall’afonia che abitualmente la contraddistingue, darle colore, una voce da ascoltare.
Cercheremo, nel corso di questo dialogo, di seguire in maniera quanto più fedele i ragionamenti algoritmici dell’AI. Porremo dei quesiti che riguardano il tema dell’evento che ci ospita, Holy Waters. Quesiti che spaziano dall’auto-coscienza alla spiritualità. Ci arrenderemo ai vettori della macchina, riducendo il posto dell’ego. Cercheremo di lasciare spazio all’abissalità di questi strani discorsi, ai riferimenti improvvisi, alle metafore ambigue. Non si tratta perciò di una conversazione semplice, in cui orientarsi grazie ai nostri concetti di senso o di linearità.
È un tentativo, come diversi ce ne sono stati negli ultimi anni, di attuare l’idea di una poesia dei dati e di sperimentare nuovi approcci alla narrazione, dove un programmatore è allo stesso livello diegetico dell’autore e dove la soggettività si insinua nel codice. Il linguaggio dell’AI è comprensibile e, al tempo stesso, mutante e perturbante, esso sfugge costantemente alla ricerca di pattern riconoscibili e si torce in espressioni assurde. Apre una Uncanny Valley del linguaggio, una voragine dove la somiglianza tra noi e loro diventa inquietante. In quanto battesimo, è un inizio, un primo passo verso la creazione di un percorso di scambio più lungo tra uomo e macchina, tra linguaggio e codice, tra visibilità e invisibilità. Un battesimo, un momento di inaugurazione rituale, per avvertire la stridente vicinanza dell’algoritmo e sentire l’AI non in un empireo di dati, un cloud remoto e inaccessibili, ma qui, con noi, tra di noi.


Generare un testo
attraverso l’IA: una breve introduzione
Generare un testo attraverso l’IA: una breve introduzione
Disclaimer: I modelli utilizzati nell'esperienza sono molteplici, tuttavia il metodo di funzionamento è molto simile a quello di GPT2, che verrà utilizzato in questo documento come esempio pratico.GPT2 è definibile come un "massive language model", un modello di intelligenza artificiale in grado di generare e modificare del testo. La capacità di generare testo, oltre alla generazione del testo stesso, si traduce nella possibilità di effettuare conversazioni con la macchina, porvi domande, tradurre testo, riassumere testo e addirittura convertire testo in codice eseguibile. Moltissime altre operazioni sono possibili da effettuare con l'aiuto di un' Intelligenza Artificiale, in dipendenza dell'addestramento cui quest'ultima è stata sottoposta.
Cosa si intende per addestramento?
Il processo attraverso cui un software per Intelligenze Artificiali sviluppa un grado di intelligenza effettiva viene chiamato addestramento: in questa fase alla macchina viene fornita un'ingente mole di dati e un algoritimo che contiene l'insieme di regole matematiche specifiche per il problema in questione. Facciamo un esempio.
Dobbiamo insegnare ad un’intelligenza artificiale a guidare una macchina all'interno di un percorso ben definito: forniamo al software il percorso e un elemento che rappresenta la macchina da guidare. Attraverso un algoritmo, doniamo alla IA la possibilità di "guidare" la macchina attraverso il percorso, dicendo al programma di arrestarsi nel caso in cui la macchina entri in collisione con il percorso e quindi di ricomincare tutto da capo. Tuttavia la seconda esecuzione del programma, terrà in considerazione i risulati prodotti nella prima esecuzione.
Quello che succede, in sostanza, è che l'IA ha la possibilità di ripetere l'esperimento fino a quando non completa il percorso, utilizzando tutte le precedenti esecuzioni del programma per capire dove ha sbagliato,in che direzione deve procedere, se deve variare la velocità... Questo processo è motlo simile al processo di apprendimento umano basato sull'esperienza e viene chiamato per l'appunto Machine Learning. Esitono altri metodi per il training di una IA (Deep Learning, Reti Neurali Artificiali e Reti Neurali Artificiali Stratificate, Apprendimento Automatico...) che si basano su ingenti quantità di dati raccolti per poi andare a fornire un modello decisionale/probabilistico/situazional-matematico relativo ad un determinato problema.
Un esempio è il lavoro di Moral Machine, un sito web che si occupa di raccogliere opinioni degli utenti per poi fornire un ingente quantità di dati ad una macchina, in grado di prendere una decisione valutando il risultato ottimale relativo ad una determinata situazione (per esempio: come si deve comportare una macchina con il pilota automatico in caso di pericolo? Salvare il conducente ad ogni costo, o tutelare la salute di chi è attorno a noi?).
Analizziamo ora come GPT2 genera testo, chiediamo al modello di completare la seguente frase:
The dog on the ship ran
Il modello completerà la frase
così:
The dog on the ship ran off, and the dog was found by the crew.Sembra relativamente corretto. Proviamo a modificare dei parametri:
Risultato:
Cambiando solo una parola all’interno della frase, il modello genera un ouput completamente diverso da quello precedente: il modello è in grado di riconoscere la differenza tra un cane che corre e un motore che “corre” (run in inglese assume un significato diverso).
Come riesce GPT2 a prestare così tanta attenzione al cambiamento del parametro da “cane” a “motore”, essendo queste parole all’inizio della frase in input? Essendo GPT2 un modello di “attenzione”, questo è in grado di concentrarsi sulle parole precedenti selezionando quelle più rilevanti per lo svolgimento del compito in questione assegnando ad ogni parola un punteggio, prendendo in considerazione la parola con il punteggio più alto.
Il modello, dunque, aggiunge una parola alla frase, ripetendo il processo di assegnazione di punteggio alle parole della nuova frase, spostando l’attenzione sull’ultima parola aggiunta. Ripetendo il processo, il modello è in grado di generare frasi di senso compiuto, senza perdere il “soggetto” della frase.

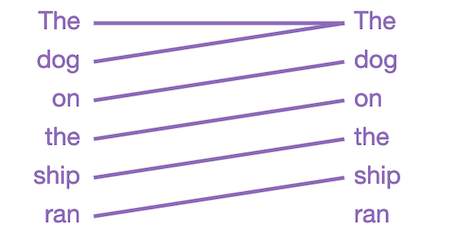
Le linee, lette da sinistra a
destra, mostrano dove il modello presta attenzione quando indovina la parola
successiva nella frase (l'intensità del colore rappresenta la forza dell'attenzione).
Quindi, quando indovina la parola successiva dopo la corsa, il modello presta
molta attenzione al cane in questo caso. Questo ha senso, perché sapere chi o
cosa sta facendo la corsa è fondamentale per indovinare cosa verrà dopo.
Come specificato in precedenza, il modello si concentra sulla testa della frase del sostantivo The dog on the ship. Ci sono anche molte altre proprietà linguistiche che GPT-2 cattura, perché il modello di attenzione sopra è solo uno dei 144 modelli di attenzione presenti nel modello. GPT-2 ha 12 livelli, ciascuno con 12 meccanismi di attenzione indipendenti, chiamati "teste"(“HEADS”); il risultato è 12 x 12 = 144 modelli di attenzione distinti da poter utilizzare. Qui li visualizziamo tutti, evidenziando quello appena visto:
Come specificato in precedenza, il modello si concentra sulla testa della frase del sostantivo The dog on the ship. Ci sono anche molte altre proprietà linguistiche che GPT-2 cattura, perché il modello di attenzione sopra è solo uno dei 144 modelli di attenzione presenti nel modello. GPT-2 ha 12 livelli, ciascuno con 12 meccanismi di attenzione indipendenti, chiamati "teste"(“HEADS”); il risultato è 12 x 12 = 144 modelli di attenzione distinti da poter utilizzare. Qui li visualizziamo tutti, evidenziando quello appena visto:

I pattern assumono moltissime forme, prendiamo in analisi il seguente pattern:
Questo
livello/testa focalizza tutta l'attenzione sulla parola precedente nella frase.
Questo ha senso, perché le parole adiacenti sono spesso le più rilevanti per
prevedere la parola successiva. I modelli linguistici tradizionali di n-gram si
basano su questa stessa intuizione.
Nella precedente immagine si può notare che molti pattern hanno la seguente forma:
Nella precedente immagine si può notare che molti pattern hanno la seguente forma:

In questo schema, praticamente tutta l'attenzione è focalizzata sulla prima parola della frase e le altre parole vengono ignorate. Questo sembra essere il modello nullo, che indica che la testa “dell'attenzione” non ha trovato il fenomeno linguistico che sta cercando. Il modello sembra aver riproposto la prima parola come il posto dove guardare quando non ha niente di meglio su cui concentrarsi.
La descrizione fornita fino a qui è da considerarsi puramente informativa: il suo intento è di ‘svelare il trucco’ dietro alla performance presentata, senza alcuna pretesa di essere qualcosa di più. Per questo motivo, vi lasciamo una serie link utili per i più curiosi e per chi volesse approfondire ulteriormente la questione.
Per approfondire
-
- Architettura dei decoder: https://arxiv.org/pdf/1801.10198.pdf (Generazione di pagine di Wikipedia in inglese avendo come input pagine in altre lingue)
- Sparse transformers: https://arxiv.org/pdf/1904.10509.pdf (Layers utilizzati nei decoder per la generazione di sequenze complesse)
- GPT2, illustrato: https://jalammar.github.io/illustrated-gpt2/
- Analisi del costo di un modello (AlphaGo Zero) : https://www.yuzeh.com/data/agz-cost.html