
ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ
A report
29 June 2022 - #AI #art #machinelearning - Alessandro Y. Longo -

On July 26, 2021, with this post, Alessandro on REINCANTAMENTO inaugurated a path of research and exploration of art generated through machine learning algorithms. One year and 35 published experiments later (but many more generated), we try to draw some conclusions, putting together the material gathered in a year of underground research, especially in light of the explosion of interest in the topic of generative models that accompanied the release of DALL-E 2 and its mini version, which went viral in recent weeks. The hype is tangible again, and this is leading to the cyclical return of sensationalist claims, such as the idea that Google's LamDA model is becoming sentient (spoiler: it is not). As in so many other cases, the teaching of Public Enemy still applies: don't believe the hype.
Disclaimer: All images were generated by the author within the past year except where otherwise indicated.
Disclaimer: All images were generated by the author within the past year except where otherwise indicated.
The birth of Promptism (July-Aprile)
On July 21, 2021, I was posting on re.incantamento Instagram a small clip titled '𝖗𝖆𝖛𝖎𝖓𝖌 𝖆𝖕𝖕𝖆𝖗𝖆𝖙𝖚𝖘', described as "a bubbling neon magma in which sketched figures seem to dance." It was the beginning of my year of experimenting with image generation through machine learning models. From the very first piece, I tried to keep a few simple rules:
- I titled all images and videos.
-
I never published the exact textual input with which the images and videos were generated.
- I always indicated the model used

They were instinctive choices to 'elevate' the generations to small works in their own right and characterize them with their own uniqueness beyond the text-image correspondence. As we shall see, the text used as input (also called prompt) expresses more than just representation.
The beginning of the ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ experiment should be contextualized in its historical moment, spring-summer 2021. This is the moment when two different models, VQGAN and CLIP are combined by different artists and engineers in the field, primarily Ryan Murdock and Katherine Crowson, and disseminated through Google Colab. So we have the combination of new means of generation (the VQGAN+CLIP assemblage) and a renewed use of means of distribution: the storm is perfect and within days the issue goes viral on Twitter and Reddit. Let's go through the components in detail.
VQGAN, is a generative adversarial neural network (Generative Adversarial Network, known as GAN) that is able to generate images similar to others (but not from a query); it was first proposed in the paper "Taming Transformers" at the University of Heidelberg (2020), so titled precisely because it combines Convutional Neural Networks - traditionally used for images - with Transformers - traditionally used for language but here trained on image datasets.
CLIP (Contrastive Language-Image Pre-training) is another neural network that can determine the correspondence between a caption (or prompt) and an image. CLIP was proposed by OpenAI in January 2021 and is not a true generative model as much as a model that associates images and text. In the video below, artist Remi Durant has created a method to visualize how CLIP "sees" images.
These models require some computational power to be used on a machine locally and, at the same time, a fair amount of agility with the programming language used (in this case, Python). For this reason, using Google Colab as a means of distributing models turned out to be a winning choice and generated a perfect storm. But what exactly is Colab?
Google Colaboratory (usually referred to as Colab) is a programming environment based on 'cloud' technology ( which allows Python code to run on servers that have access to GPUs (fast processors originally created for graphics) and are actually leased from Google. Colab has both a free and a pro version and a rather simple interface that combines code and text making it very easy to create guided and easy-to-use notebooks (that is the name of a Colab page). Within a short period of time, the notebooks multiplied, improving with small variations and adjustments (see Zoetrope 5, with more advanced features): certainly, the openness to a wider audience makes this process faster and more chaotic than the classic peer review mechanisms of academic papers or the closed processes of private companies (we will return to this topic).
The accessibility and at the same time the (relative) power of these means is also attractive to REINCANTAMENTO, which has already been exploring theoretically (but not only) the idea of creativity in the time of automated machines for a year. So I set out to create images forlornly and try to figure out the little tricks to best play with these black boxes. In fact, my programming knowledge does not allow me to act drastically on the code, and as a result, the experience becomes a continuous hand-to-hand with parameters that are clear enough for me to manipulate.
Among these options, one of the first I find myself experimenting with is generation from an existing image, which replaces the gray box from which the process usually starts.

ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ #3: ☄️ 𝔄𝔩𝔤𝔬𝔯𝔦𝔱𝔥𝔪𝔦𝔠 𝔙𝔞𝔯𝔦𝔞𝔱𝔦𝔬𝔫 𝔬𝔫
‘𝔊𝔦𝔲𝔡𝔦𝔷𝔦𝔬 𝔘𝔫𝔦𝔳𝔢𝔯𝔰𝔞𝔩𝔢’ by 𝔏𝔲𝔠𝔞 𝔖𝔦𝔤𝔫𝔬𝔯𝔢𝔩𝔩𝔦. Generated with Zoetrope 5
The first algorithmic variation starts from Luca Signorelli's Giudizio Universale: although my output control capabilities at the time were still limited, we can already see how VQGAN+CLIP operates through a decomposition of the initial image, which is progressively disassembled. What remains more or less stable is the fundamental structure of the input image, its topological composition, and the way the figures are allocated in space. A later experiment, number 28, is another curious transformation - titled 𝕭𝖆𝖘𝖖𝖚𝖎𝖆𝖙 𝕺𝖚𝖗𝖔𝖇𝖔𝖗𝖔𝖘 - starting with a concentric figure of smiley faces: as is evident, the only constant in the transformation is the topological configuration of the image, which is reflected in the permanence of the main circle.

By 𝕭𝖆𝖘𝖖𝖚𝖎𝖆𝖙 𝕺𝖚𝖗𝖔𝖇𝖔𝖗𝖔𝖘 I had already understood and obtained the main skill needed to control the generative process in some way: engineering the prompt. What does this mean? Simply, through specific keywords, the generative process focuses on some clusters of images rather than others. In the present case, associating the description of the image with the words in the style of Basquiat produces a result that moves around the palette and characteristics of the American artist's work. The textual parameter should be understood not only as a descriptive and representational tool as much as a real expressive medium with different functionalities.
𝔢𝔫𝔠𝔥𝔞𝔫𝔱𝔢𝔡 𝔳𝔦𝔰𝔦𝔬𝔫 🔅, experiment #8, uses as part of the descriptive input "re-enchantment of the world" and as expressive input keywords such as "esoteric style," "fluorescent," "psychedelic," and so on.
𝔢𝔫𝔠𝔥𝔞𝔫𝔱𝔢𝔡 𝔳𝔦𝔰𝔦𝔬𝔫 🔅, experiment #8, uses as part of the descriptive input "re-enchantment of the world" and as expressive input keywords such as "esoteric style," "fluorescent," "psychedelic," and so on.

ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ #8: 𝔢𝔫𝔠𝔥𝔞𝔫𝔱𝔢𝔡 𝔳𝔦𝔰𝔦𝔬𝔫 🔅
Using "rendered in Unreal 3D" as keywords, for example, allows you to get quasi-3D images because CLIP goes to match generative numbers with sections of its database that contain three-dimensional renders made with the famous software. Similarly, it is possible to obtain pixel art-style results or simply improve the quality and style of one's image with the expression "trending on Artstation," which takes the most clicked images on the well-known platform as a reference. Let's take a look at some examples of results obtained with tactical adjustments to the prompt.

ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ #10: 𝔪𝔬𝔯𝔫𝔦𝔫𝔤 𝔰𝔱𝔞𝔯𝔰 🎇. An instance of simulated tridimensionality

ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ #13: 𝖉𝖆𝖓𝖈𝖎𝖓𝖌 𝖆𝖜𝖆𝖞 🪅 Generated with Text2Pixel

ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ Unreleased: 𝖓𝖊𝖙𝖜𝖔𝖗𝖐𝖘 𝖔𝖋 𝖓𝖊𝖙𝖜𝖔𝖗𝖐𝖘. Generated with Text2Pixel

ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ #15: '𝒲𝐻𝒜𝒯 𝑀𝐼𝒢𝐻𝒯 𝒜 𝐹𝒰𝒯𝒰𝑅𝐸 𝑅𝐸𝒱𝒪𝐿𝒰𝒯𝐼𝒪𝒩 𝐿𝒪𝒪𝒦 𝐿𝐼𝒦𝐸 Generated withVQGAN+CLIP
As the image below shows, controlling certain keywords has a decisive effect on the final result. Artist Remi Durant has also posted a site where one can observe the various art styles "contained" in VQGAN+CLIP by associating an artist's name with their prompt.
If we imagine our generative model as a boat launched into an ocean of data, then text manipulation is how we can guide this boat and lead it to follow certain currents instead of others.

Keywords manipulation with VQGAN+CLIP
Here the whole game of generative art in its current form is played out. With VQGAN+CLIP first and DALL-E 2 later, we can speak of the birth of a new artistic current, promptism, or the art of the prompt, the input we give to the machine that represents an early form of dialogue we can have with the black box. The manifesto of this movement was incubated within Latent Space's Discord server, and then was written by GTP-3, the best machine learning model in text generation and also developed by Open AI.
“It is important to note that the hidden Prompts are not in-line with the original purpose of prompts. The goal is to “challenge the viewer”, so the viewer may experience a cognitive shift and their perceptions changed. At its core, Promptism is a movement that encourages artists to think outside of the box and explore what can be done with the art. The Prompt may be a small image or a text, and may appear to be anything from an advertisement to a warning.”
Prompt artists are developing a grammar, a xeno-language for communicating with the mathematical entity and collaborating with it to achieve the desired result. The very idea of "desired result" is rather shaky in this area: one can approach the terminal with a clear idea of what one wants to achieve only to be progressively diverted from the results proposed by the machine over the course of iterations. Or, in other cases, the best result is the one obtained in the first round of iterations and the final product disappoints expectations. Even more than with visual experiments, this feeling of progressive abysmality is had by using textual models. Last December with some friends we organized a small performance in which we also worked with some texts generated by GTP-2. On that occasion I wrote:
"We will try, in the course of this dialogue, to follow as faithfully as possible the algorithmic reasoning of AI. [...] We will surrender to the vectors of the machine, reducing the place of the ego. We will try to leave room for the abysmality of these strange conversations, the sudden references, and the ambiguous metaphors. Therefore, this is not an easy conversation, in which to orient ourselves thanks to our concepts of meaning or linearity. It is an attempt, like several there have been in recent years, to implement the idea of given poetry and to experiment with new approaches to storytelling, where a programmer is at the same diegetic level as the author and where subjectivity creeps into the code. The language of AI is comprehensible and, at the same time, mutant and perturbing; it constantly escapes the search for recognizable patterns and twists into absurd expressions. It opens an Uncanny Valley of language, a chasm where the similarity between us and them becomes uncanny."

ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ Unreleased: Angelic Predator. Generated withDALL-E Mini“It is important to note that the hidden Prompts are not in-line with the original purpose of prompts. The goal is to “challenge the viewer”, so the viewer may experience a cognitive shift and their perceptions changed. At its core, Promptism is a movement that encourages artists to think outside of the box and explore what can be done with the art. The Prompt may be a small image or a text, and may appear to be anything from an advertisement to a warning.”
Prompt artists are developing a grammar, a xeno-language for communicating with the mathematical entity and collaborating with it to achieve the desired result. The very idea of "desired result" is rather shaky in this area: one can approach the terminal with a clear idea of what one wants to achieve only to be progressively diverted from the results proposed by the machine over the course of iterations. Or, in other cases, the best result is the one obtained in the first round of iterations and the final product disappoints expectations. Even more than with visual experiments, this feeling of progressive abysmality is had by using textual models. Last December with some friends we organized a small performance in which we also worked with some texts generated by GTP-2. On that occasion I wrote:
"We will try, in the course of this dialogue, to follow as faithfully as possible the algorithmic reasoning of AI. [...] We will surrender to the vectors of the machine, reducing the place of the ego. We will try to leave room for the abysmality of these strange conversations, the sudden references, and the ambiguous metaphors. Therefore, this is not an easy conversation, in which to orient ourselves thanks to our concepts of meaning or linearity. It is an attempt, like several there have been in recent years, to implement the idea of given poetry and to experiment with new approaches to storytelling, where a programmer is at the same diegetic level as the author and where subjectivity creeps into the code. The language of AI is comprehensible and, at the same time, mutant and perturbing; it constantly escapes the search for recognizable patterns and twists into absurd expressions. It opens an Uncanny Valley of language, a chasm where the similarity between us and them becomes uncanny."

Thus, on the one hand, control through the use of keywords suited to certain visual styles; on the other hand, the constant fall of meaning into algorithmic randomness leads to unexpected directions. If this ambiguous feeling had hitherto been experienced by a select few, the spread of these algorithms in the form of powerful ready-to-use Colabs has brought this experience to many more people (including me): the symbiosis and co-creation between algorithms and humankind is now a reality. In the words of Mat Dryhurst:
"It's like jamming, giving and receiving feedback while refining an idea with an inhuman collaborator, seamlessly. It feels intuitively like a tool for making art."
Automating Narrative (April-June)

ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ Unreleased: The portrait of a Majestic Gnome. Generated with Latent Majesty Diffusion 1.6
After this "first wave" of text-to-image model virality, it was OpenAI again that ignited tempers with the release of the already mythological DALL-E 2 in April this year. The basic operation of DALL-E 2 is the same as VQGAN+CLIP: generating images from textual input. What is new is the quality of generation: DALL-E 2 has a realistic high-resolution style that can add and remove elements taking into account shadows, reflections, and textures. OpenAI's creature is based on a type of model called "diffusion": a technique from statistical physics introduced in 2015 in machine learning and then improved to the current level in a series of papers between 2020 and 2021. What is the fundamental idea behind diffusion models? A kind of dual motion operates on the image: at first, the image is filled with noise in the first moment of diffusion (forward diffusion); the second moment (reverse diffusion) "cleans" the image of noise and reconstructs it. This process is iterative and occurs through a series of steps so that the model can learn better. This video is a detailed explanation in case you would like to learn more.
The excellent results of DALL-E 2 and its rival Imagen (owned by Google) can be seen in the fidelity to the prompt and the accuracy in which the details are reproduced.

A golden-billed chrome duck arguing with an angry turtle in a forest. Generated with Imagen

Homer Simpson crossing the multiverses. Generated with DALL E 2
Both models reproduce the critical issues typical of large machine learning models (such as GTP-3). The progress of these techniques relies on the use of increasingly large models with millions of parameters and trained on immense databases of images. The computational cost and consequent energy cost, of these mega-machines, grow in parallel with their improved performance. Add to that the fact that the AI industry has an inherent extractive nature and requires more and more raw materials to maintain its race toward progress, as scholar Kate Crawford masterfully recounted. Researcher Timnit Gebru calculated that about 300 tons of CO2 are emitted to train a large language model-a considerable and worrisome figure. In the public reception of these models, it is strange how this fact has escaped the attention of many* commentators*, if we consider instead the culture war that has erupted around NFTs precisely in light of their environmental impact. Let's open a small aside: fortunately, scholars such as Roy Schwartz, Jesse Dodge, Noah A. Smith, and Oren Etzioni have brought to light the urgency of building sustainable machine learning models. The main idea is to improve the efficiency of models so that they require smaller amounts of data: this means reshaping reasoning from a probabilistic perspective, which is able to arrive at the correct output without having to analyze millions of pieces of data. It also involves changing industry metrics. Instead of rewarding only the models that achieve the best results in absolute terms, other measures related to ecological impact should be kept in mind. The computational efficiency of the model, the electrical consumption, and the resulting C02 emissions-these are the criteria that should guide the industry.
Finally, it should be pointed out that not many research centers are able to have such a large amount of GPUs to train models: this leads to increased inequalities and prevents smaller players from doing cutting-edge research. OpenAI's policy in this regard is paradigmatic. In fact, despite the company's name, access to DALL-E 2 is not 'open' at all, and in order to test it at the moment, one must apply and hope to be accepted. Moreover, OpenAI has not published the model and its parameters (as it had not done for GTP-3 either) and access is provided only through their proprietary API. A similar argument can be made for Imagen: the justification adopted in both cases is that companies want to study the effects of their innovative new tools in greater depth before feeding them to the masses. These models in fact contain the "usual" biases in the datasets that characterize the entire AI industry and can consequently be easily used to create discriminatory and offensive content. With this in mind, the industry's most powerful models are becoming more opaque and inscrutable every day. Finally, the idea that present learning methods are improving quantitatively but not qualitatively is becoming more and more prevalent, and new potential models are appearing on the scene.
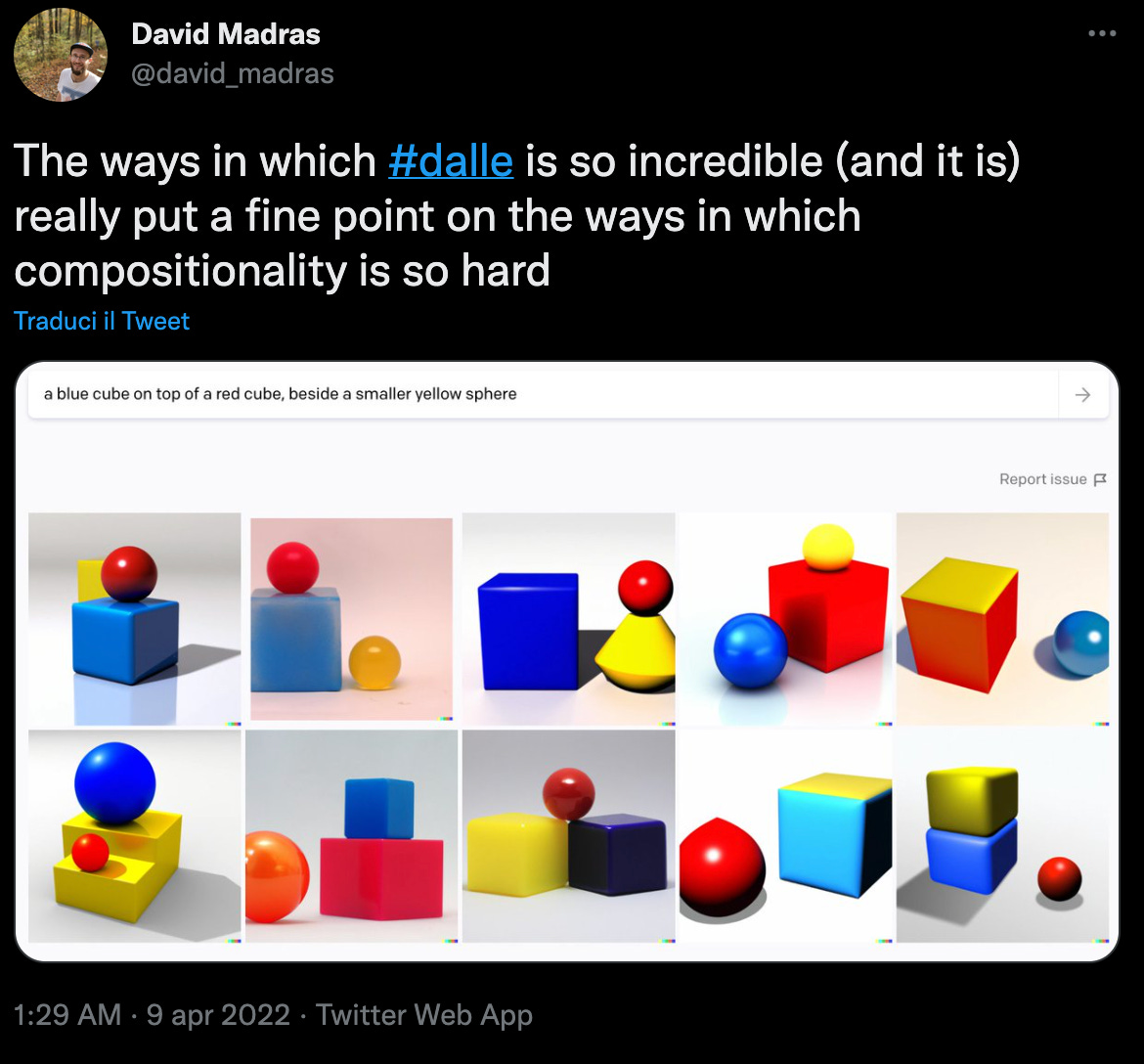
DALL·E 2 doesn’t understand Bongard’s problem
Precisely because of the scarcity of access, our experiment does not include results generated with DALL-E 2. The great hype caused by DALL-E 2 and the scarcity of access to the model has caused a great deal of attention to DALL-E Mini, a de-powered version of the famous model, but made open-source on the huggingface.com platform (another site for accessing online machine learning models) and appealing because of the simplicity of the interface and the form in which the image is generated. According to its creator, more than 200,000 people use DALL-E Mini every day, a number that continues to grow. A Twitter account called "Weird Dall-E Mini Generations" created in February has more than 934,000 followers at the time of publication. DALL-E Mini was created by trying to replicate the mechanisms of OpenAI's spread model. The popularity surrounding DALL-E Mini has even surpassed the explosion of VQGAN+CLIP the previous summer. How can this phenomenon be explained?
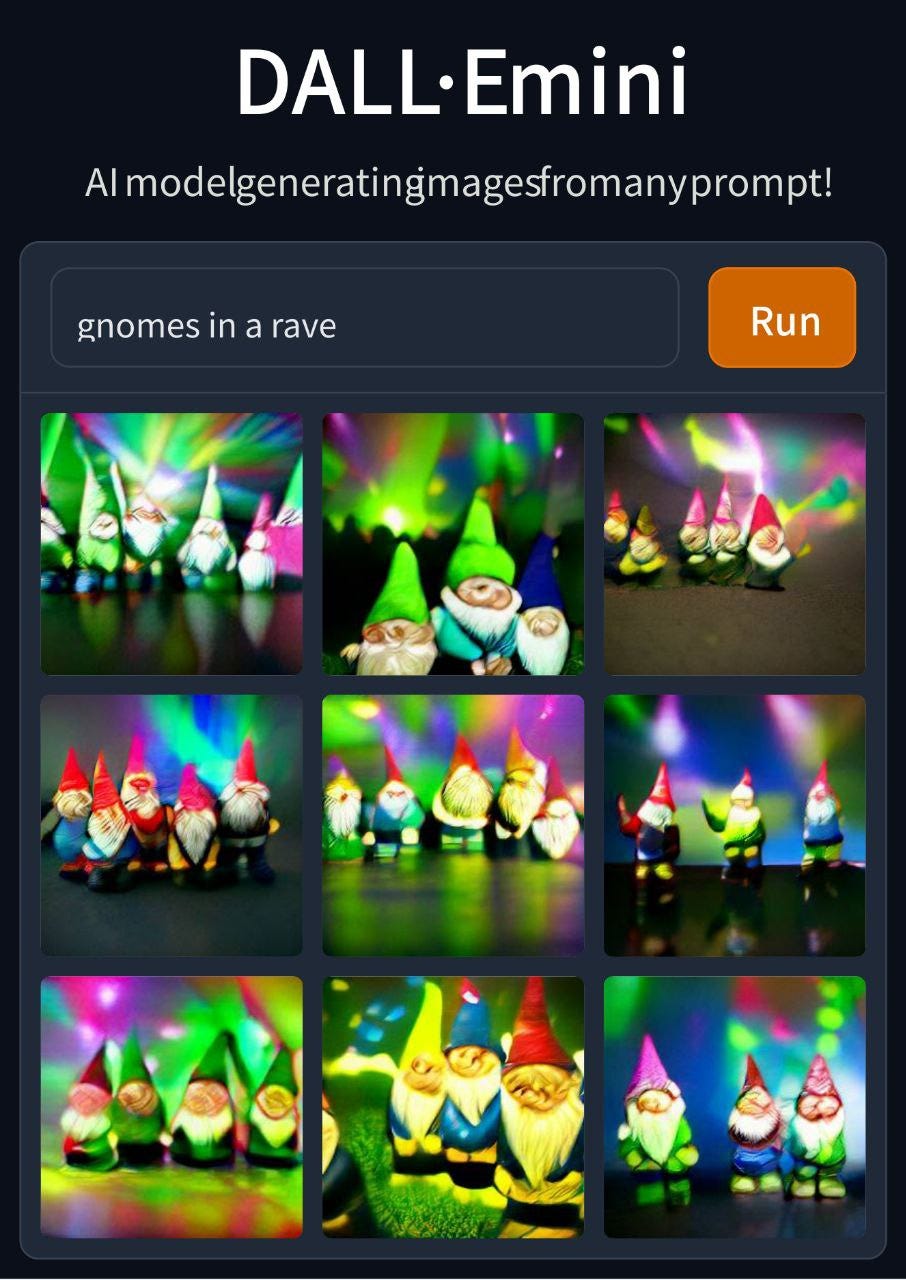
ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ Unreleased: Gnomes in a rave. Generated with DALL E Mini
Jay Springinett on his blog compared the grid structure of DAll-E MINI's output with the political compass meme, capturing in its particular visual organization the reason for its virality:
“One powerful side of compasses is the fact that it gives all options/possibilities at once, overloading the mind and forcing you to think about it.”
The memetic format coupled with the extreme ease of use of DAll-E MINI has brought synthetic image generation to a new level of popularity. As with the magic notebooks from which this report takes its title, the alchemy between means of distribution and means of generation has led to a new wave of online expressiveness. Interestingly, despite the attempts of large corporations and academia to keep the power of these mediums in check, they are nevertheless being disseminated and distributed through a process of spillover to a wider audience, giving rise to a kind of punk moment of machine learning, where quality and efficiency are sacrificed in exchange for speed and accessibility thus leading to the emergence of a digital subculture, combining a taste for net art with the ethos of peer-to-peer communities. Code is shared transparently and modifiable by all, the most interesting parameters and keywords are shared, and sub-communities are born around the ritual of synthetic image generation.
The results are already curious, and as we explore the most lopsided corners of social media we become aware of the many funny experiments that these tools are enabling. Let's look at a brief list of them:
The common trait of these experiments is a trend toward automation of the narrative space: we use models such as DALL-E and VQGAN to provide us with cues, drafts, and prototypes with which to begin creating a story. The human element is elevated to the director of the generative process, to the curator of the various sections of a project, first created by AI and then stitched together by a human mind. DALL-E and the like cannot create something properly new since they rely on the processing of past data. A generative model can revive the style of a dead artist (see the Basquiat example cited above) but they cannot invent a brand new style. Therefore, automation is not absolute (and I doubt it can be anytime soon) but relative to an initial moment when a spark is generated that can bring an entire narrative landscape to life. For example, in experiment #35, we tried to bring a Socialist Gundam to life:

ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ #35: 🤖🧧𝖘𝖔𝖈𝖎𝖆𝖑𝖎𝖘𝖙 𝖌𝖚𝖓𝖉𝖆𝖒 🧧🤖. Generated with Text2ImageV5
If we perceive these patterns as surfaces containing narrative landscapes ready to be conjured up, the act of writing a prompt becomes an alchemical gesture, a magic formula capable of bringing to life a world hidden until that moment. Ursula K. Le Guin wrote:
“Technology is the active human interface with the material world. [...] I don’t know how to build and power a refrigerator, or program a computer, but I don’t know how to make a fishhook or a pair of shoes, either. I could learn. We all can learn. That’s the neat thing about technologies. They’re what we can learn to do.”
The latent potential of these models will be expressed through what we humans learn to do and express through them. The dissemination to a wider audience that we have witnessed in recent months is the first step in this direction, but we must - as humanity - continue to learn and stay close to the danger of AI - ‘staying with the trouble' as Donna Haraway put it - so that we can be participants in the democratic and participatory co-evolution of these technologies. Not to believe the hype but to understand with enchanted rationality the progress in space. For this reason, the ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ experiment will continue on REINCANTAMENTO in the months to come, trying out new models (now it is time for Latent Majesty Diffusion 1.6) and monitoring the structural impact of these new technologies. At the same time, the collision between generative models and online creative subcommunities should not be underestimated: that is where the most interesting fruits of new human-machine collaborations will develop in the future.

ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ Unreleased: Tribal Bot. Generated with Latent Majesty Diffusion 1.6