
ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ
Un report
29 Giugno 2022 - #AI #arte #machinelearning - Alessandro Y. Longo -

Il 26 Luglio 2021, con questo post, Alessandro su REINCANTAMENTO inaugurava un percorso di ricerca ed esplorazione dell’arte generata tramite algoritmi di machine learning. Un anno e 35 esperimenti pubblicati dopo (ma molti di più generati), proviamo a trarre qualche conclusione, mettendo insieme il materiale raccolto in un anno di ricerca sotterranea, soprattutto alla luce dell’esplosione di interesse verso il tema dei modelli generativi che ha accompagnato l’uscita di DALL-E 2 e la sua versione mini, diventata virale nelle scorse settimane. L’hype è di nuovo tangibile e questo sta portando al ciclico ritorno di affermazioni sensazionalistiche, come l’idea che il modello LamDA di Google stia diventando senziente (spoiler: non lo sta diventando). Come in tanti altri casi, l’insegnamento dei Public Enemy è ancora valido: don’t believe the hype.
Disclaimer: tutte le immagini sono state generate dall’autore nel corso dell’ultimo anno se non dove differentemente indicato.
La nascita del promptismo (July-Aprile)
Il 21 luglio 2021, pubblicavo sulla pagina di re.incantamento una piccola clip intitolata ‘𝖗𝖆𝖛𝖎𝖓𝖌 𝖆𝖕𝖕𝖆𝖗𝖆𝖙𝖚𝖘’, descritta come “un magma gorgogliante al neon in cui sembrano danzare figure abbozzate”. Era l’inizio del mio anno di sperimentazioni con la generazione di immagini tramite modelli di machine learning. Sin dal primo pezzo, ho cercato di mantenere qualche semplice regola:
- Ho titolato tutte le immagini e i video
-
Non ho mai pubblicato l’input testuale preciso con cui le immagini e i video sono stati generati.
- Ho indicato sempre il modello utilizzato

Sono state scelte istintive per ‘elevare’ le generazioni a piccole opere a sé stanti e caratterizzare con una propria unicità al di là della corrispondenza testo-immagine. Come vedremo, il testo usato come input (chiamato anche prompt) esprime molto di più che una semplice rappresentanza.
L’inizio dell’esperimento di ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ va contestualizzato nel suo momento storico, la primavera-estate 2021. Si tratta del momento in cui vengono combinati due diversi modelli, VQGAN e CLIP da divers* artist* e ingegner* nel settore, in primis Ryan Murdock e Katherine Crowson, e diffusi tramite Google Colab. Abbiamo quindi la combinazione di nuovi mezzi di generazione (l’assemblaggio VQGAN+CLIP) e un uso rinnovato dei mezzi di distribuzione: la tempesta è perfetta e in pochi giorni la questione diventa virale su Twitter e Reddit. Andiamo a vedere nel dettaglio i componenti (perdonate i numerosi anglicismi).
VQGAN, è una rete neurale generativa avversaria (Generative Adversarial Network, noto come GAN) che è in grado di generare immagini simili ad altre (ma non a partire da una richiesta); è stata proposta per la prima volta nel paper "Taming Transformers" dell'Università di Heidelberg (2020), così titolato proprio perché combina le Convutional Neural Network - tradizionalmente utilizzate per le immagini - con i Transformers - tradizionalmente utilizzati per il linguaggio ma qui allenati su dataset di immagini.
CLIP (Contrastive Language–Image Pre-training) è un'altra rete neurale in grado di determinare la corrispondenza tra una didascalia (o una richiesta) e un'immagine. CLIP è stata proposta da OpenAI nel gennaio 2021 e non è un vero modello generativo quanto un modello che associa immagini e testi. Nel video qui sotto, l’artista Remi Durant ha creato un metodo per visualizzare come CLIP “vede” le immagini.

Questi modelli richiedono una certa potenza computazionale per essere usati su una macchina in locale e, al tempo stesso, una discreta agilità con il linguaggio di programmazione usato (in questo caso, Python). Per questa ragione, l'utilizzo di Google Colab come mezzo di distribuzione dei modelli si è rivelato essere una scelta vincente e ha generato una tempesta perfetta. Ma cos'è esattamente Colab?
Google Colaboratory (solitamente indicato come Colab) è un ambiente di programmazione basato su tecnologia ‘cloud’ ( che consente di eseguire codice Python su server che hanno accesso alle GPU (processori veloci originariamente creati per la grafica) e che vengono di fatto affittati da Google. Colab possiede sia una versione gratuita che una versione pro e un’interfaccia piuttosto semplice che combina codice e testo rendendo molto semplice creare dei notebook (questo il nome di una pagina Colab) guidati e facili da utilizzare. Nell’arco di poco tempo, i notebook si moltiplicano, migliorando con piccole varianti e aggiustamenti (si veda Zoetrope 5, con features più avanzate): sicuramente, l’apertura a un pubblico più ampio rende questo processo più rapido e caotico rispetto ai classici meccanismi di peer review dei paper accademici o ai processi chiusi delle aziende private (ritorneremo sul tema).
L’accessibilità e al tempo stesso la (relativa) potenza di questi mezzi è attraente anche per il progetto di REINCANTAMENTO, che già da un anno esplorava teoricamente (ma non solo) l’idea di creatività ai tempi delle macchine automatiche. Mi metto quindi a creare immagini forsennatamente e a cercare di capire i piccoli trucchi per giocare al meglio con queste scatole nere. La mia conoscenza di programmazione infatti non mi consente di agire drasticamente sul codice e, di conseguenza, l’esperienza diventa un continuo corpo a corpo con i parametri che mi sono abbastanza chiari per poter essere manipolati.
Tra queste opzioni, una delle prime con cui mi trovo a sperimentare è la generazione a partire da un’immagine già esistente, che si sostituisce al riquadro grigio da cui di solito parte il processo.

La prima variazione algoritmica parte dal Giudizio Universale di Luca Signorelli: sebbene le mie capacità di controllo dell’output all’epoca fossero ancora limitate, possiamo già notare come VQGAN+CLIP operi attraverso una scomposizione dell’immagine iniziale, che viene progressivamente disassemblata. Ciò che rimane più o meno stabile è la struttura fondamentale dell’immagine di input, la sua composizione topologica e il modo in cui le figure sono allocate nello spazio. Un esperimento successivo, il numero 28, è un’altra curiosa trasformazione - intitolata 𝕭𝖆𝖘𝖖𝖚𝖎𝖆𝖙 𝕺𝖚𝖗𝖔𝖇𝖔𝖗𝖔𝖘 - a partire da una figura concentrica di faccine sorridenti: come è evidente, l’unica costante nella trasformazione è la configurazione topologica dell’immagine che viene rispecchiata nella permanenza del cerchio principale.

Con 𝕭𝖆𝖘𝖖𝖚𝖎𝖆𝖙 𝕺𝖚𝖗𝖔𝖇𝖔𝖗𝖔𝖘 avevo già capito e ottenuto la principale competenza necessaria per controllare in qualche modo il processo generativo: l'ingegnerizzazione del prompt. Cosa significa? Semplicemente, tramite specifiche parole chiave, il processo generativo si concentra su alcuni cluster di immagini piuttosto che altri. Nel caso in esame, associando la descrizione dell’immagine alle parole in the style of Basquiat si ottiene un risultato che si muove intorno alla palette e alle caratteristiche dell’opera dell’artista americano. Il parametro testuale non va inteso solo come uno strumento descrittivo e rappresentazionale quanto un vero e proprio mezzo espressivo dalle diverse funzionalità.
𝔢𝔫𝔠𝔥𝔞𝔫𝔱𝔢𝔡 𝔳𝔦𝔰𝔦𝔬𝔫 🔅, esperimento #8, usa come parte dell’input descrittivo “reincantamento del mondo” e come input espressivo keywords quali “esoteric style, “fluorescent”, “psychedelic” e così via.
𝔢𝔫𝔠𝔥𝔞𝔫𝔱𝔢𝔡 𝔳𝔦𝔰𝔦𝔬𝔫 🔅, esperimento #8, usa come parte dell’input descrittivo “reincantamento del mondo” e come input espressivo keywords quali “esoteric style, “fluorescent”, “psychedelic” e così via.

ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ #8: 𝔢𝔫𝔠𝔥𝔞𝔫𝔱𝔢𝔡 𝔳𝔦𝔰𝔦𝔬𝔫 🔅
Usare come keywords “rendered in Unreal 3D”, per esempio, permette di ottenere immagini quasi-3D perché CLIP va ad abbinare i numeri generativi con le sezioni del suo database che contengono render tridimensionali realizzati con il famoso software. Allo stesso modo è possibile ottenere risultati in stile pixel art o semplicemente migliorare la qualità e lo stile della propria immagine con l’espressione “trending on Artstation" che prende come riferimento le immagini più cliccate sulla nota piattaforma. Vediamo qualche esempio di risultati ottenuti con aggiustamenti tattici del prompt.

ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ #10: 𝔪𝔬𝔯𝔫𝔦𝔫𝔤 𝔰𝔱𝔞𝔯𝔰 🎇. Un esempio di tridimensionalità “illusoria”

 ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ Unreleased: 𝖓𝖊𝖙𝖜𝖔𝖗𝖐𝖘 𝖔𝖋 𝖓𝖊𝖙𝖜𝖔𝖗𝖐𝖘. Generato con Text2Pixel
ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ Unreleased: 𝖓𝖊𝖙𝖜𝖔𝖗𝖐𝖘 𝖔𝖋 𝖓𝖊𝖙𝖜𝖔𝖗𝖐𝖘. Generato con Text2Pixel
Come mostra l’immagine sottostante, il controllo di alcune parole chiave ha un effetto decisivo sul risultato finale. L’artista Remi Durant ha anche pubblicato un sito in cui si possono osservare i vari stili artistici “contenuti” in VQGAN+CLIP associando il nome di un’artista al proprio prompt. Se immaginiamo il nostro modello generativo come una barca lanciata in un oceano di dati, allora la manipolazione del testo è il modo in cui possiamo guidare questa barca e portarla a seguire certe correnti invece che altre.

Manipolazione delle parole chiave con VQGAN+CLIP
Qui si gioca l’intera partita dell’arte generativa nella sua corrente forma. Con VQGAN+CLIP prima e DALL-E 2 poi, si può parlare di nascita di una nuova corrente artistica, il promptismo, ovvero l’arte del prompt, l’input che diamo alla macchina e che rappresenta una prima forma di dialogo che possiamo avere con la scatola nera. Il manifesto di questo movimento, incubato all'interno del server Discord di Latent Space, e poi è stato scritto da GTP-3, il modello di machine learning migliore nella generazione di testi e sviluppato anch’esso da Open AI.
“È importante notare che i prompt nascosti non sono in linea con lo scopo originale dei prompt. L'obiettivo è quello di "sfidare lo spettatore", in modo che quest'ultimo possa sperimentare uno spostamento cognitivo e cambiare le proprie percezioni. In fondo, il Promptismo è un movimento che incoraggia gli artisti a pensare fuori dagli schemi e a esplorare ciò che si può fare con l'arte. Il Prompt può essere una piccola immagine o un testo, e può sembrare qualsiasi cosa, da una pubblicità a un avvertimento.”
Gli artisti promptisti stanno sviluppando una grammatica, uno xeno-linguaggio per comunicare con l’entità matematica e collaborare con essa per raggiungere il risultato desiderato. L’idea stessa di "risultato desiderato” è piuttosto traballante in questo ambito: ci si può approcciare al terminale con un’idea precisa di ciò che si vuole ottenere per poi venire progressivamente deviati dai risultati proposti dalla macchina nel corso delle iterazioni. O, in altri casi, il risultato migliore è quello ottenuto nel primo ciclo di iterazioni e il prodotto finale delude le aspettative. Ancora di più che con gli esperimenti visivi, questa sensazione di progressiva abissalità la si ha usando i modelli testuali. Lo scorso dicembre con alcuni amici abbiamo organizzato una piccola performance in cui abbiamo lavorato anche con alcuni testi generati da GTP-2. In quell’occasione scrivevo:
"Cercheremo, nel corso di questo dialogo, di seguire in maniera quanto più fedele i ragionamenti algoritmici dell’AI. [...] Ci arrenderemo ai vettori della macchina, riducendo il posto dell’ego. Cercheremo di lasciare spazio all’abissalità di questi strani discorsi, ai riferimenti improvvisi, alle metafore ambigue. Non si tratta perciò di una conversazione semplice, in cui orientarsi grazie ai nostri concetti di senso o di linearità. È un tentativo, come diversi ce ne sono stati negli ultimi anni, di attuare l’idea di una data poetry e di sperimentare nuovi approcci alla narrazione, dove un programmatore è allo stesso livello diegetico dell’autore e dove la soggettività si insinua nel codice. Il linguaggio dell’AI è comprensibile e, al tempo stesso, mutante e perturbante, esso sfugge costantemente alla ricerca di pattern riconoscibili e si torce in espressioni assurde. Apre una Uncanny Valley del linguaggio, una voragine dove la somiglianza tra noi e loro diventa inquietante.”

“È importante notare che i prompt nascosti non sono in linea con lo scopo originale dei prompt. L'obiettivo è quello di "sfidare lo spettatore", in modo che quest'ultimo possa sperimentare uno spostamento cognitivo e cambiare le proprie percezioni. In fondo, il Promptismo è un movimento che incoraggia gli artisti a pensare fuori dagli schemi e a esplorare ciò che si può fare con l'arte. Il Prompt può essere una piccola immagine o un testo, e può sembrare qualsiasi cosa, da una pubblicità a un avvertimento.”
Gli artisti promptisti stanno sviluppando una grammatica, uno xeno-linguaggio per comunicare con l’entità matematica e collaborare con essa per raggiungere il risultato desiderato. L’idea stessa di "risultato desiderato” è piuttosto traballante in questo ambito: ci si può approcciare al terminale con un’idea precisa di ciò che si vuole ottenere per poi venire progressivamente deviati dai risultati proposti dalla macchina nel corso delle iterazioni. O, in altri casi, il risultato migliore è quello ottenuto nel primo ciclo di iterazioni e il prodotto finale delude le aspettative. Ancora di più che con gli esperimenti visivi, questa sensazione di progressiva abissalità la si ha usando i modelli testuali. Lo scorso dicembre con alcuni amici abbiamo organizzato una piccola performance in cui abbiamo lavorato anche con alcuni testi generati da GTP-2. In quell’occasione scrivevo:
"Cercheremo, nel corso di questo dialogo, di seguire in maniera quanto più fedele i ragionamenti algoritmici dell’AI. [...] Ci arrenderemo ai vettori della macchina, riducendo il posto dell’ego. Cercheremo di lasciare spazio all’abissalità di questi strani discorsi, ai riferimenti improvvisi, alle metafore ambigue. Non si tratta perciò di una conversazione semplice, in cui orientarsi grazie ai nostri concetti di senso o di linearità. È un tentativo, come diversi ce ne sono stati negli ultimi anni, di attuare l’idea di una data poetry e di sperimentare nuovi approcci alla narrazione, dove un programmatore è allo stesso livello diegetico dell’autore e dove la soggettività si insinua nel codice. Il linguaggio dell’AI è comprensibile e, al tempo stesso, mutante e perturbante, esso sfugge costantemente alla ricerca di pattern riconoscibili e si torce in espressioni assurde. Apre una Uncanny Valley del linguaggio, una voragine dove la somiglianza tra noi e loro diventa inquietante.”

Da una parte, quindi, il controllo tramite l’uso di parole chiave adatte a certi stili visivi; dall’altra, la costante caduta del significato nella randomicità algoritmica che porta a direzioni inaspettate. Se questa ambigua sensazione era stata finora esperita da pochə elettə, la diffusione di questi algoritmi nella forma di potenti Colab pronti all’uso ha portato questa esperienza a tante altre persone (me incluso): la simbiosi e la co-creazione tra algoritmi e genere umano è oggi una realtà. Nelle parole di Mat Dryhurst:
“È come fare una jam, dare e ricevere feedback mentre si affina un'idea con un collaboratore inumano, senza soluzione di continuità. Si sente intuitivamente come uno strumento per fare arte.”
Automatizzare la narrativa (Aprile-Giugno)

Dopo questa “prima ondata” di viralità dei modelli text-to-image, è stata nuovamente OpenAI a infiammare gli animi con il rilascio del già mitologico DALL·E 2 nell’aprile di quest’anno. Il funzionamento di base di DALL·E 2 è lo stesso di VQGAN+CLIP: generare immagini a partire da input testuali. La novità è la qualità della generazione: DALL·E 2 ha uno stile realistico ad alta risoluzione può aggiungere e rimuovere elementi tenendo conto di ombre, riflessi e texture. La creatura di OpenAI si basa su un tipo di modello chiamato “diffusione”: una tecnica proveniente dalla fisica statistica introdotta nel 2015 nell’ambito del machine learning e poi migliorata fino al livello attuale in una serie di paper tra il 2020 e il 2021. Qual è l’idea fondamentale dietro i modelli di diffusion? Una sorta di doppio movimento opera sull’immagine: all’inizio, l’immagine viene riempita di rumore in un primo momento di diffusione (forward diffusion); il secondo momento (reverse diffusion) “ripulisce” l’immagine dal rumore e la ricostruisce. Questo processo è iterativo e avviene attraverso una serie di passaggi così che il modello possa imparare meglio. Questo video è una spiegazione dettagliata nel caso voleste saperne di più.
I risultati eccellenti di DALL·E 2 e del suo rivale Imagen (di proprietà di Google) sono visibili nella fedeltà al prompt e nella precisione in cui vengono riprodotti i dettagli.

Un'anatra cromata dal becco d'oro che discute con una tartaruga arrabbiata in una foresta. Generato con Imagen

Homer Simpson che attraversa i multiversi. Generato con DALL E 2
Entrambi i modelli riproducono le criticità tipiche dei grossi modelli di machine learning (come GTP-3). Il progresso di queste tecniche si fonda sull’utilizzo di modelli sempre più grandi, con milioni di parametri e allenati su database immensi di immagini. Il costo computazionale, e il conseguente costo energetico, di queste mega-macchine cresce in parallelo al miglioramento delle loro prestazioni. Si aggiunge inoltre il fatto che l’industria dell’AI abbia un intrinseco carattere estrattivo e richiede sempre più materie prime per mantenere la sua corsa verso il progresso, come ha raccontato magistralmente la studiosa Kate Crawford.
La ricercatrice Timnit Gebru ha calcolato che per allenare un grande modello linguistico vengono emesse circa 300 tonnellate di CO2: una cifra considerevole e preoccupante. Nella ricezione pubblica di questi modelli, è strano come questo fatto sia sfuggito all’attenzione di molt* commentator*, se consideriamo invece la culture war scoppiata intorno agli NFT proprio in luce del loro impatto ambientale. Apriamo un piccolo inciso: fortunatamente, studiosi come Roy Schwartz, Jesse Dodge, Noah A. Smith e Oren Etzioni hanno portato alla luce l’urgenza di costruire modelli di machine learning isostenibili. L’idea principale è di migliorare l’efficienza dei modelli così che richiedono minori quantità di dati: ciò significa rimodellare i ragionamenti secondo un’ottica probabilistica, che sia in grado di arrivare all’output corretto senza dover analizzare milioni di dati. Inoltre, si tratta di cambiare le metriche dell’industria. Invece di premiare soltanto i modelli che ottengono i risultati migliori in termini assoluti, bisognerebbe tenere a mente altre misure legate all’impatto ecologico. L’efficienza computazionale del modello, il consumo elettrico e le conseguenti emissioni di C02: sono questi i criteri che dovrebbero guidare il settore.
Infine, va sottolineato come non siano molti i centri di ricerca in grado di disporre di una tale quantità di GPU per allenare i modelli: questo porta ad un aumento delle disuguaglianze e impedisce agli attori più piccoli di fare ricerca d’avanguardia. La politica di OpenAI in questo senso è paradigmatica.
Infatti, nonostante il nome della compagnia, l’accesso a DALL·E 2 non è affatto ‘open’ e per poterlo provare al momento è necessario fare richiesta e sperare di essere accettati. Inoltre, OpenAI non ha pubblicato il modello e i suoi parametri (come non aveva fatto neanche per GTP-3) e l’accesso è fornito soltanto tramite la loro API proprietaria. Un discorso simile si può fare anche per Imagen: la giustificazione adottata in entrambi i casi è che le compagnie vogliono studiare più in profondità gli effetti dei loro nuovi strumenti innovativi prima di darli in pasto alle masse.
Questi modelli infatti contengono i “soliti” bias nei dataset che caratterizzano l’intera industria AI e possono di conseguenza essere usati facilmente per creare contenuti discriminatori e offensivi. Con questa ragione, i modelli più potenti dell’industria stanno diventando ogni giorno più opachi e imperscrutabili. Infine, l’idea che i presenti metodi di apprendimento stiamo migliorando quantitativamente ma non qualitativamente è sempre più diffusa e nuovi potenziali modelli si affacciano sulla scena.
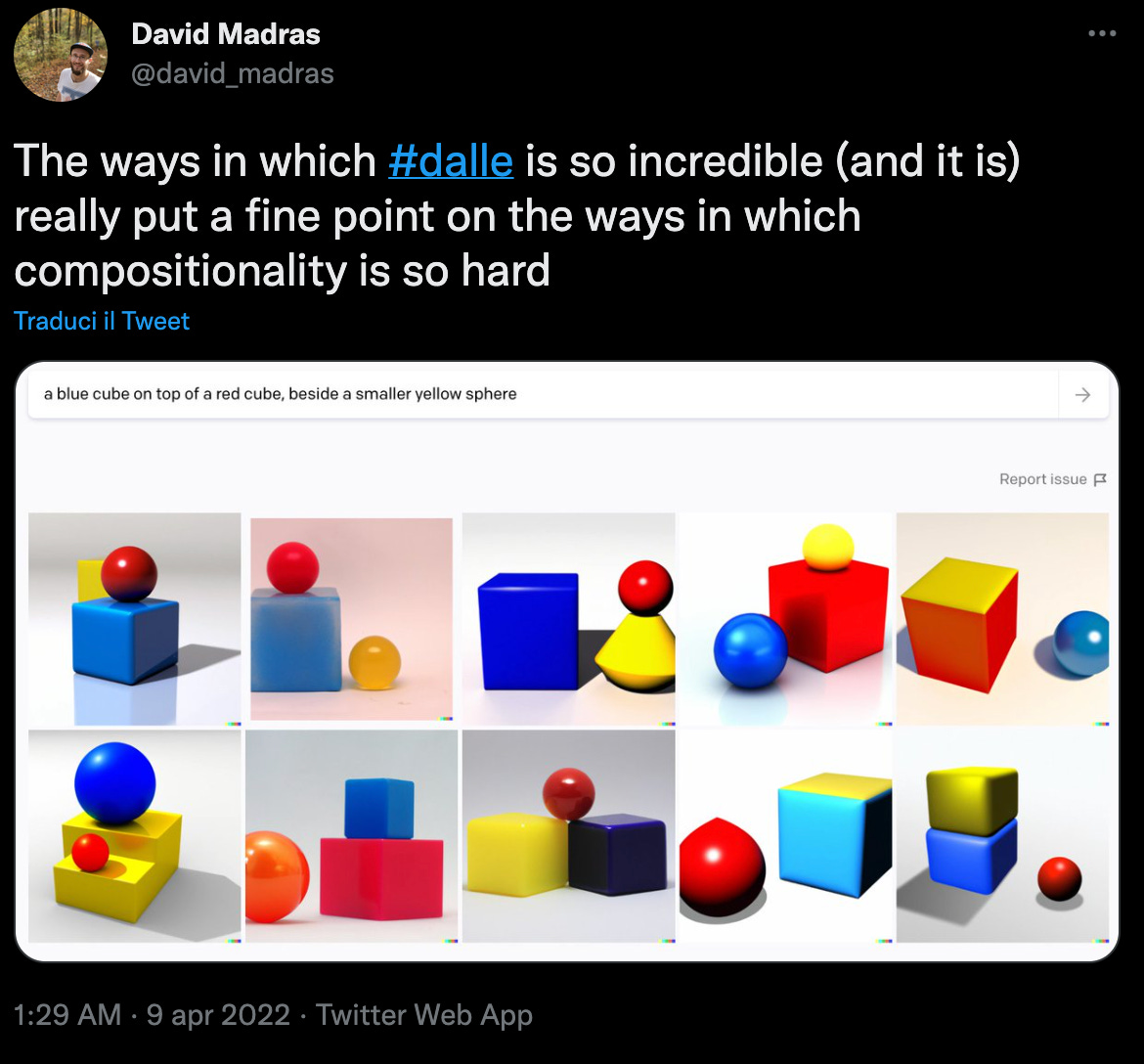
DALL·E 2 non comprende il problema di Bongard
Proprio per la scarsità di accesso, il nostro esperimento non include risultati generati con DALL·E 2. Il grande hype provocato da DALL·E 2 e la scarsità di accesso al modello hanno causato una grande attenzione verso DALL·E Mini, una versione depotenziata del famoso modello, ma resa open-source sulla piattaforma huggingface.com (un altro sito per accedere a modelli di machine learning online) e accattivante per la semplicità dell’interfaccia e la forma in cui l’immagine viene generata. Secondo il suo creatore, più di 200.000 persone utilizzano DALL·E Mini ogni giorno, un numero in continua crescita. Un account Twitter chiamato "Weird Dall-E Mini Generations", creato a Febbraio, ha più di 934.000 follower al momento della pubblicazione. DALL·E Mini è stato creato cercando di riprodurre i meccanismi del modello a diffusione di OpenAI. La viralità che ha caratterizzato DALL·E Mini ha persino superato l’esplosione di VQGAN+CLIP dell’estate precedente. Come si spiega questo fenomeno?
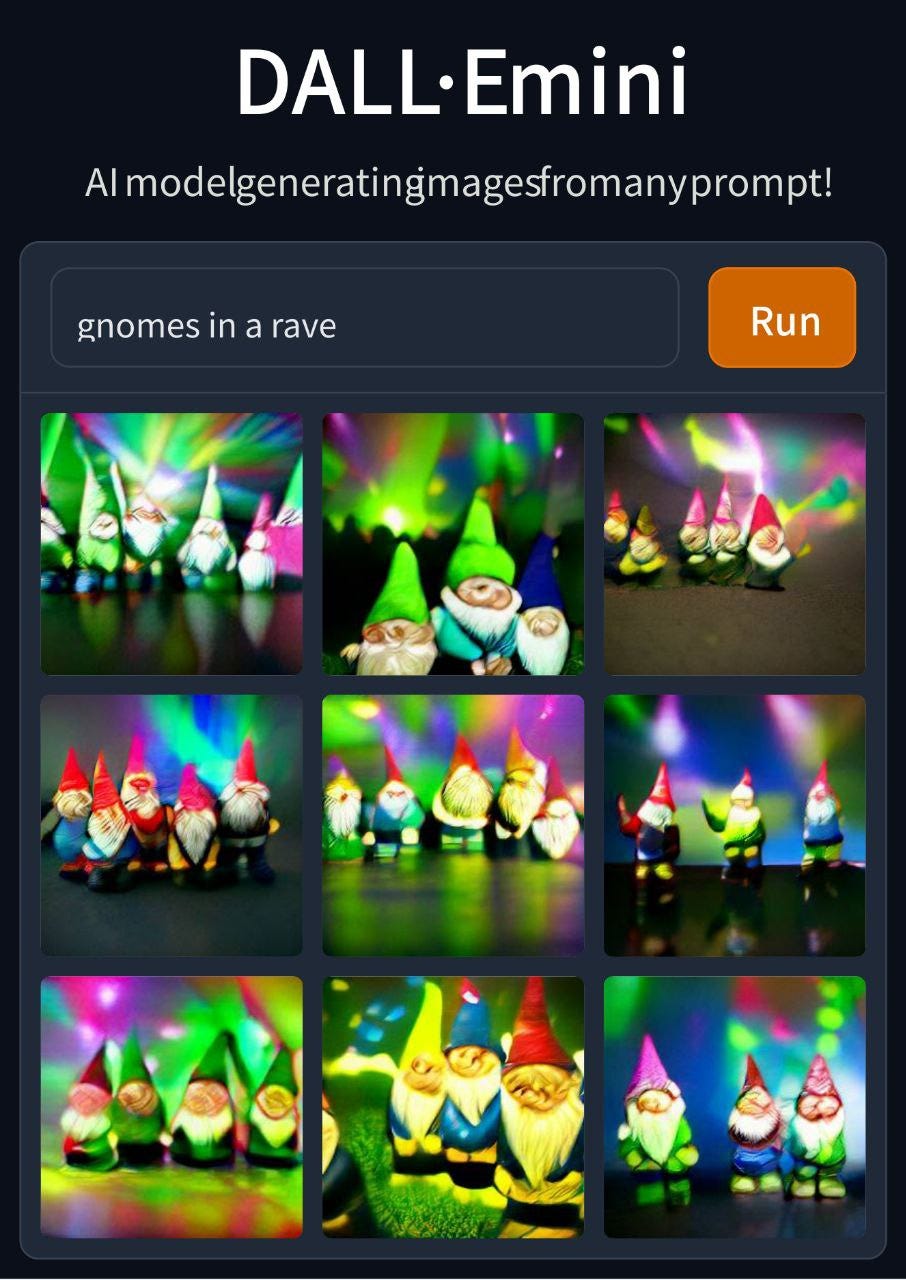
Jay Springinett sul suo blog ha paragonato la struttura a griglia dell’output di DAll-E MINI con il meme del political compass cogliendo nella sua particolare organizzazione visiva la ragione della sua viralità:
“Un lato potente dei compass è il fatto di fornire tutte le opzioni/possibilità in una volta sola, sovraccaricando la mente e costringendo a riflettere.”
Il formato memetico unito all’estrema facilità d’uso di DAll-E MINI hanno portato la generazione di immagini sintetiche ad un nuovo livello di popolarità. Come per i magic notebooks da cui prende il titolo questo report, l’alchimia tra mezzi di distribuzione e mezzi di generazione ha portato ad una nuova ondata di espressività online. E’ interessante notare come, nonostante i tentativi delle grandi corporation e dell’accademia di mantenere sotto controllo il potere di questi mezzi, essi vengano comunque diffusi e distribuiti attraverso un processo di spillover verso un pubblico più ampio, dando vita ad una sorta di momento punk del machine learning, dove la qualità e l’efficienza sono sacrificate in cambio di velocità e accessibilità portando così alla nascita di una sottocultura digitale, che unisce il gusto per net art con l’ethos delle comunità peer-to-peer. Il codice si condivide in maniera trasparente e modificabile da tutti, si condividono i parametri e le parole chiave più interessanti e sotto-comunità nascono intorno al rituale della generazione di immagini sintetiche.
I risultati sono già curiosi e esplorando gli angoli più sbilenchi dei social media ci si accorge di tanti, buffi esperimenti che questi strumenti stanno permettendo. Vediamone un breve elenco:
Il tratto comune di questi esperimenti è una tendenza verso l’automazione dello spazio narrativo: usiamo modelli come DALL-E e VQGAN per fornirci spunti, bozze e prototipi con i quali iniziare a creare una storia. L’elemento umano si eleva a direttore d’orchestra del processo generativo, a curatore delle varie sezioni di un progetto, prima create dall’AI e poi cucite insieme da una mente umana. DALL-E e simili non possono creare qualcosa di propriamente nuovo poiché si basano sull’elaborazione di dati passati. Un modello generativo può far rivivere lo stile di un artista morto (si veda l’esempio di Basquiat citato sopra) ma non possono inventare uno stile inedito. Per questo, l’automazione non è assoluta (e dubito che potrà presto esserlo) ma relativa a un primo momento in cui viene generata una scintilla che può dare vita a un intero panorama narrativo. Per esempio, nell’esperimento #35, abbiamo provato a dare vita a un Gundam Socialista:

Se percepiamo questi modelli come superfici che contengono panorami narrativi pronti a essere evocati, l’atto di scrivere un prompt diventa un gesto alchemico, una formula magica capace di dare vita ad un mondo nascosto fino a quel momento. Ursula K. Le Guin scriveva che:
“La tecnologia è l'interfaccia attiva dell'uomo con il mondo materiale [...] Non so come costruire e alimentare un frigorifero, o programmare un computer, ma non so nemmeno come costruire un amo da pesca o un paio di scarpe. Posso imparare. Tutti possiamo imparare. È questo il bello delle tecnologie. Sono ciò che possiamo imparare a fare”
Il potenziale latente di questi modelli verrà espresso attraverso ciò che noi umani impareremo a fare ed esprimere attraverso di essi. La diffusione ad un pubblico più ampio a cui abbiamo assistito negli ultimi mesi è un primo passo in questa direzione, ma dobbiamo - come umanità - continuare a imparare e a stare vicino al pericolo dell’AI - ‘staying with the trouble’ per dirla con Donna Haraway - per poter essere partecipi della co-evoluzione democratica e partecipata di queste tecnologie. Non credere all’hype ma comprendere con razionalità incantata i progressi nello spazio. Per questo motivo, l’esperimento di ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ continuerà sulle pagine di REINCANTAMENTO anche nei mesi successivi, provando nuovi modelli (ora è il momento di Latent Majesty Diffusion 1.6) e monitorando l’impatto strutturale di queste nuove tecnologie. Al tempo stesso, non va sottovalutato la collisione tra i modelli generativi e le sotto comunità creative online: è lì che nel futuro si svilupperanno i frutti più interessanti delle nuove collaborazioni uomo-macchina.
 ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ Unreleased: Robot Tribale. Generato con con Latent Majesty Diffusion 1.6
ᗰᗩGIᑕ_ᑎOTEᗷOOKᔕ Unreleased: Robot Tribale. Generato con con Latent Majesty Diffusion 1.6